



小组依托人工智能与大数据分析等技术,面向多源跨模态知识资源与教学行为两类教育数据,开展图谱构建、智能导学、精准推荐、定制辅导、精细评价、情景感知等关键技术研究,解决互联网智慧教育中导学、推荐、辅教、评价等环节的技术难题,探索智慧教育服务模式,形成自主可控的技术体系。
小组培养出不同行业的优秀人才。孙霞博士、宋凌云博士、王萌博士、张玲玲和马杰博士分别进入西北大学、西北工业大学、东南大学、西安交通大学任教;蒋路、吴朝晖和叶俊廷分别进入卡内基梅隆大学和宾夕法尼亚州立大学攻读博士。胡云华博士进入微软亚洲研究院工作并成立高科技公司;多名硕士进入摩根斯坦利、微软亚研院、百度、阿里巴巴、腾讯、美团等国内外知名企业工作;小组与国外研究机构建立良好的合作关系,刘文强、姚思雨、田振华、吴蓓等博士生曾在斯坦福、昆士兰、CMU、德国亚琛工业大学交流访问。
碎片化知识的位置分散、内容片面、结构无序三个特性对大数据时代的知识获取与认知提出了新挑战。以智慧教育为载体,围绕多模态碎片知识的表征、融合、推理开展理论、方法研究与应用。
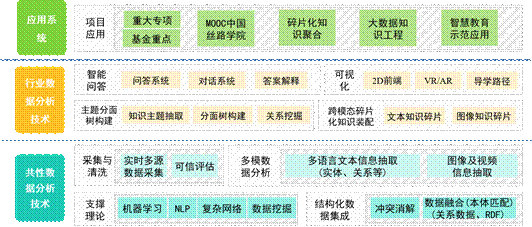
小组研究框架
刘均 教授 博士生导师。
西安交大二级教授,博士生导师,国家“万人计划”科技创新领军人才,斯坦福大学高级访问学者,IEEE高级会员。担任IEEE TNNLS、Information Fusion编委以及多个国际期刊的客座编辑。近年来,承担了国家重点研发计划项目、国家863课题、国家自然科学基金重点项目、国家自然科学基金原创项目。在IJCV、IEEE TPAMI、IEEE TKDE、ICDE、KDD等重要期刊与国际会议上发表论文百余篇,出版学术专著2部,获得ISSRE 2016、ICBK 2018等最佳论文奖。授权发明专利20项。获国家科技进步二等奖、国家教学成果二等奖,中国自动化学会科技进步特等奖以及多项省部级科技奖励。获陕西省优秀博士论文指导教师、王宽诚育人奖等奖励与荣誉。研究方向:自然语言处理、计算机视觉、智慧教育。
主页:https://gr.xjtu.edu.cn/en/web/liukeen
魏笔凡 西安交通大学研究员
主持2项NSFC面上项目、2项重点研发子课题等。在 ACL、WWW、IEEE TKDE、TIP,TNNLS,CSVT等国际期刊会议上发表论文40多篇,授权发明专利10余项。研究方向:教学资源分析挖掘、教育图谱构建及智能问答。获陕西省自然科学一等奖、陕西省技术发明一等奖。
张玲玲 副教授 博士生导师
近年来,主持NSFC青年项目等科研项目6项。在TPAMI、CVPR、TIP、TKDE、TCSVT等高水平期刊会议发表论文17篇,出版中英文学术著作3部。研究方向:小样本与零样本学习、计算机视觉、知识图谱、智慧教育
小组成员
博 士:潘雨黛、梁曦、王佳欣、王雅娴、王绍伟、赵天哲、吴文俊、张戬、张新宇、傅玮萍、徐方植、李波、孙俏
研 三:仉珂、陈一苇、仲宇杰、张泽民、柴琦、岳浩
研 二:胡蕴璋、马英洪、胡健翔、李逸飞、杨昌林、郭晨阳、黄牧野、任铭、韩佳伟
研 一:茹燕池、郭天霖、张宇舜、孙辰扬、陈一心、朱佳印、朱隆吉、唐熙、渠宁、齐世豪、赵宏涛、黄家兴、王庆康
以在线教育中智能问答为应用载体,对跨媒体问题的可解释推理开展理论方法研究与实证测试。研究方向将包括问题理解、示意图理解、知识库问答、阅读理解,视觉问答、智能对话等。
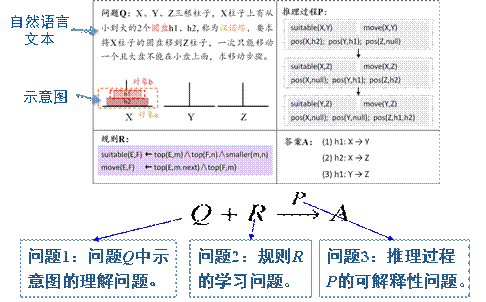
研究成果1:逻辑可解释推理
时序知识图谱(TKG)针对传统KG上现实世界的知识通常会随着时间的推移而演变这一局限性引入时间信息来更全面地表示知识。相关研究表明,在TKG上不能直接实现可微逻辑规则学习与推理,主要归因于以下两大挑战:第一,TKG包含不同的信息,例如结构依赖、时间动态和隐藏逻辑规则,难以合并在一起并实现完全覆盖;第二,逻辑规则表示是离散的和符号的,导致逻辑规则与神经网络的连续计算之间存在自然差距。
课题组提出一个统一的框架TECHS和一种新的前向注意规则归纳(FARI)算法,能够有效处理TKGs中的复杂信息和隐藏的逻辑规则,同时也实现了可解释的推理过程。其中,TECHS框架主要包括一个时序图编码器和一个逻辑解码器。编码器使用图卷积网络(GCN)来嵌入拓扑结构和时间动态,同时引入了通用的时间编码和异构注意力机制来确定实体之间的不同边权重。解码器则集成了命题和一阶推理来找到答案,并使用了一个包含查询实体和实体-时间对节点的推理图来进行迭代扩展。由此上述两个挑战得到解决,模型实现了在TKGs上复杂信息的有效整合与可微逻辑推理。
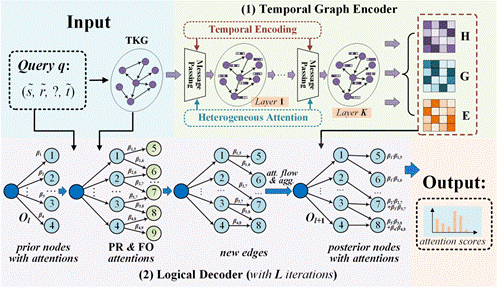
图1 TECHS框架模型图
FARI算法则利用学习到的一阶注意力权重来诱导一阶逻辑规则。在获得最后一个解码步骤中节点的注意力权重后,模型聚合具有相同实体的节点注意力以获得实体分数并进行归一化与真实标签对比,利用二元交叉损失熵进行优化。为了避免逻辑解码器中节点数量的指数爆炸增长并提高计算效率,算法遵循时间感知加权采样策略,仅针对推理图中的M个节点采样。在计算同一迭代中每条边的注意力权重后,在其中选择注意力权重 较大的 top-N 并修剪其他。当在推理图中添加额外的自我关系时,算法可以通过删除诱导得到的一阶时序逻辑规则中具有自我关系的现有原子来获得所有可能的规则(不超过长度 L)。
TECHS在五个常见的TKG数据集上进行了测试,包括ICEWS14、ICEWS18ICEWS0515、WIKI和YAGO。结果显示,与最先进的TLogic相比,TECHS显示出一定的改进,即在ICEWS14、ICEWS0515和ICEWS18数据集的所有12个指标上取得了更好的性能。TECHS在这三个数据集上平均提高了0.92%、1.65%和1.26%。此外,与最先进的TITer相比,TECHS在WIKI和YAGO数据集中MRR和Hits@10指标分别提高了0.48%、3.37%、1.77%和2.12%。实验结果表明提出的模型在建立TKG嵌入以及集成命题和一阶推理的优越性。相关成果发表在计算机顶级会议ACL2023上。
研究成果2:逻辑可解释推理
知识图谱推理是指对以三元组为载体的知识进行预测与推理。传统的推理方法有两个挑战。第一,这种方法会产生组合爆炸问题以及高时间、空间复杂度问题,影响方法实现过程中的效率;另外,仅通过知识图谱表征中的结构信息无法获得高质量规则。
针对上述问题,课题组提出一种融合结构与语义信息的逻辑规则学习方法LoTus。LoTus首次提出将外部文本与知识图谱本身的结构信息进行结合,抽取高质量一阶逻辑规则对知识图谱进行可解释推理。该方法主要从两步解决上述问题:第一,为解决统计学习方法中规则学习的序贯覆盖所导致的组合爆炸问题,LoTus设计剪枝函数,通过规则中的谓词语义相似性以及参数中实体的共现性,对一阶逻辑规则的多种原子公式的组合方式进行筛选。通过此剪枝函数,LoTus可以降低在计算规则支持度,置信度等指标时产生的较高的时间复杂度。第二,为了在计算剪枝函数时获取高质量规则,LoTus不仅考虑到了知识图谱嵌入表示中蕴含的结构信息,还通过融合实体的外部文本信息增强知识图谱嵌入表示,进而通过第一步的剪枝函数,筛选出高质量规则以提升推理结果。在此过程中,LoTus可以同时解决复杂推理的可解释性问题。
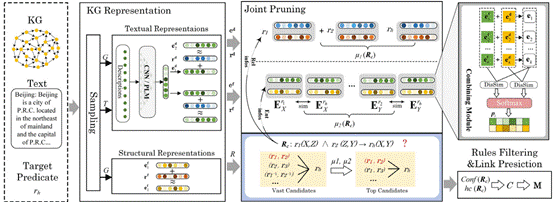
图2 LoTus框架.
实验结果表明,在三个通用知识图谱FB15K,FB15K-237以及WN18RR上,该模型相较于基线模型提升了至少1.5%。同时,在满足良好推理结果的基础上利用抽取出的高质量一阶逻辑规则,实现推理过程的可解释性。相关成果已发表在SCI一区期刊Knowledge-based Systems上。
研究成果3:LLM引导的示意图问答推理方法
示意图问答是一项颇具挑战性的任务,它要求模型基于视觉示意图图像上下文回答自然语言问题。存在两方面的技术难点:第一,该推理场景属于知识密集依赖任务,不仅要求对抽象视觉表征有深刻的理解,还要求对特定领域的知识有扎实的掌握。第二,示意图数据集通常专注于特定领域,如生物学或科学,这就要求注释者具备深入的领域背景知识,从而使得获取这类知识的成本极高。典型的示意图数据集(例如AI2D)通常仅包含数千个图表和数千个问题,这限制了样本量和注释的范围,从而为模型从初始参数状态获取充足的背景知识带来挑战,增加了后续推理过程的复杂性。为了解决上述问题,提出了CoG-DQA,一种新颖且通用的框架,它有效地引入大型语言模型作为外部知识来解决各种示意图问答场景。
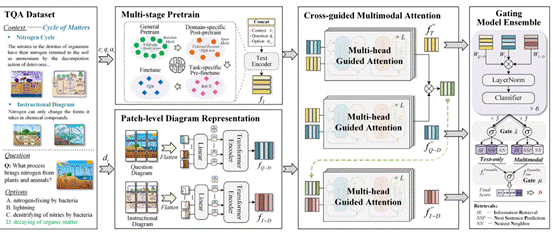
图3 COG-DQA
在CoG-DQA框架下,LLM发挥指导作用,配合图解析工具解析具有丰富背景知识的特征。 LLM和示意图解析器在此框架下都是可变的,确保模型的性能始终与最先进的技术发展保持一致。 此外,CoG-DQA 利用大模型的提示进行指导,并微调小模型进行推理,有效地弥合了领域差距。如此,技术难点一、二被有效解决。
实验结果表明,与之前最优的示意图问答模型相比,CoG-DQA模型在AI2D、SQA、TQA和 CSDQA 四个常用示意图问答数据集上取得了最好的性能,准确率指标提升了6%~11% 。相关成果投稿在计算机视觉顶级会议 CVPR 2024上。

