



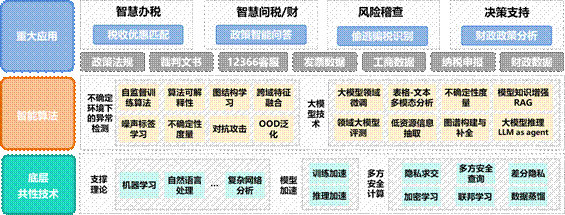
税收是国家最为重要的收入来源,发挥着组织财政收入、调节经济活动、监督经济运行等作用,被称为国家和社会高质量发展的“生命线”。智慧高效的税收征管与服务是国家治理能力的标志,也是政府在数字时代转型的必然要求。截至 2023 年 12 月,我国共有 8000 万企业纳税人和个体工商户、数亿自然人纳税人和 13 亿多社保费缴费人,相关经济社会活动产生海量涉税数据。然而这些数据通常表现出高维、海量、异构、非结构化、异常干扰等 “大数据”特性,并且专业性强,具备鲜明的领域特点,为其理解、分析与推理带来极大挑战。
小组以国家需求为导向,秉承理论与实践并重的理念,将机器学习、自然语言处理、复杂网络及知识工程理论等应用于税务大数据的理解与推理,提出了“税务知识图谱”、“纳税人利益关联网络”等概念,实现面向国家金税工程的偷逃骗税检测重大应用与面向纳税人的税收智能服务(例如财税智能问答、税收优惠政策精准匹配等)重大应用,保障税收高效征管、提升纳税服务质量,进一步推动我国税收治理现代化发展。
近年来,小组承担了国家科技支撑、自然科学基金等项目,并与税务分析行业龙头企业紧密合作,研制出国家税务大数据分析平台软件等系统。已应用于国家金税三期风险管理系统,服务全国31个省市自治区税务机关,每年为国家挽回上千亿的巨额税款;研制出面向纳税人的税收智能服务系统,已并完成商业化部署(“亿企赢”财税平台),截至2023年12月,已累计服务1304万家企业,提供超过200万条、金额总计1294.6亿的税收优惠建议。为提升国家税收征管的公平性、公正性和科学性提供了技术保障,相关成果在国际权威会议和期刊发表论文60余篇;授权国家发明专利50余项,其中12项已完成校企转化,获得2016年中国专利优秀奖。获2022年陕西省自然科学奖一等奖、2017年国家科技进步二等奖、2015年教育部科技进步一等奖、2013年中国电子学会科学技术一等奖。
税务大数据小组致力于大数据分析与智慧税务应用研究。小组基于机器学习、自然语言处理、复杂网络分析的理论与方法,并以高性能隐私计算平台作为支撑,开展不确定环境下(数据缺失、数据噪声、分布偏移)的异常检测、财税领域大模型等技术研究,支撑国家实现金税工程偷逃骗税行为识别、政策问答、税收优惠匹配等重大应用。
董博 研究员,陕西省大数据知识工程重点实验室副主任,西安交通大学跨媒体知识融合与工程应用研究所副主任。研究方向:大数据分析,智慧财政。在IEEE TKDE、IEEE TVCG、IEEE TNNLS、IJCAI、ICDE、AAAI等发表论文60余篇,授权国家发明专利30余项。先后获得2017年度国家科学技术进步二等奖(第6完成人)、2018年度陕西省技术发明一等奖(第3完成人)、2022年度陕西省自然科学一等奖(第3完成人)。
师斌 副教授,2019年6月获北京航空航天大学计算机学院计算机软件与理论专业工学博士学位,师从怀进鹏院士。主要从事数据挖掘、知识工程以及云计算等方面的研究工作。在KDD、ICDE、TKDE、TON、RAID等国际期刊、会议中发表学术论文30余篇。作为项目负责人主持、参与国家自然科学基金、国家重点研发计划、2030“新一代人工智能”重大项目等多项课题。主持研发的《国家智慧税务大数据分析平台》《云计算安全监控保障平台》《艾维云计算平台-TriCloud混合云平台》已在多个省市和不同行业应用。
彭祯,助理教授,2023年3月毕业于西安交通大学计算机科学与技术学院,获计算机科学与技术专业工学博士学位,2021年至2022年受国家留学基金委资助于新加坡南洋理工大学访学一年,并先后于2019年、2021年在腾讯AI Lab和蚂蚁金服进行研究型实习。研究方向:包括图异常检测、图表示学习、自监督学习等,在IEEE TPAMI、IEEE TKDE、WWW、IJCAI等高水平国际期刊与会议上发表论文10余篇。近年来参与国家自然科学基金重点项目、国家自然科学基金专项项目、CCF-蚂蚁科研基金项目等多项研究课题,目前作为项目负责人主持国家自然科学基金青年项目和中国博士后科学基金项目。
孙凯,助理教授,本硕博就读于北京航空航天大学计算机学院,于2023年6月获软件工程专业工学博士学位,主要从事自然语言处理方面的研究工作,包括信息抽取、情感分析、多模态学习等,在ACL,EMNLP,AAAI,WWW,TOIS等高水平会议期刊上发表论文10余篇,担任ACL 、WWW、IJCAI等国内外重要会议审稿人,多次参与科技创新2030重大项目、中国航空综合技术研究所课题等科研项目。
老师:董博、师斌、曹相湧、彭祯、孙凯
博 士:阮建飞、武乐飞、徐一明、赵锐、张载、张发、章楷豪、梁致铭
研 三:王云帆、张浩堃、赵子涵、吴雨萱、王凯、刘慧祥
研 二:曹书植、马腾、甘宇亮、张纪强、刘文龙、吴泽贤、薛韵琪、齐凯、权鹤丹、陈家润
研 一:顾可、刘丹婷、侯鹏宇、花旭、武振威、毕泽宇、牛馨葶、刘奥、魏东原
研究成果一:基于尺度变换和有监督对比的嵌套命名实体识别
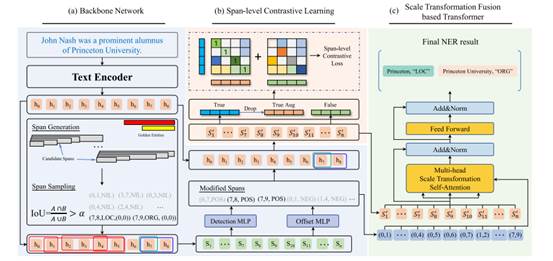
提出了一种基于尺度变换和有监督对比的嵌套命名实体识别方法。主要包括两个方面:1. 实体跨度的尺度变换。自然语言的分层组合特性导致多粒度语义,在信息抽取中表现为实体嵌套现象。嵌套结构中存在共用子序列,表明嵌套实体中存在显式的交互依赖关系。依赖关系有助于实体的类型推断。但是,现有方法忽略了实体间的相互,这降低了模型对嵌套结构的表示能力。为此,通过建立实体间尺度变换,即利用各实体相对中心位置和宽度比值的自然对数,对实体间子序列共用程度进行建模,同时利用注意力机制对实体语义进行权重分配,建立实体间交互,增强对嵌套结构的描述。2. 实体跨度表示的有监督对比。基于跨度的方法通过枚举所有候选跨度来获得跨度表示,在此过程中,会产生大量噪声样本。当前基于硬参数的样本平衡方法无法消除噪声样本导致泛化性能较差。为此,通过在实体的跨度表示上引入有监督对比损失,利用对比损失类内高内聚,类间低耦合的特性,消除噪声样本的影响,提高模型泛化性。实验证明,在嵌套实体识别数据集中,本方法达到88.69%的精确度,比现有SOTA提升3%。
研究成果二:无监督动态图表示学习方法 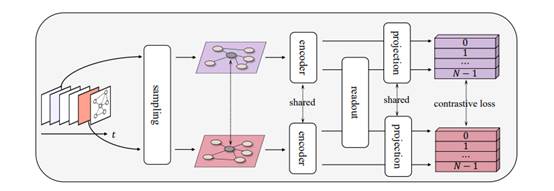
研究针对带有复杂注释的图数据类型,这是一种非常强大的数据类型,其不断发展促使我们进一步探索无监督动态图表示方法。其中一个代表性的范例是图对比学习。它通过最大化统计图的增强视图之间的互信息来构建自监督信号。然而,在增强过程中,语义和标签可能会发生变化,导致下游任务的性能显著下降。在动态图上,这个缺点会被大幅放大。为了解决这个问题,我们设计了一个简单而有效的框架,名为CLDG。首先,我们详细说明了动态图在不同层次上具有时间平移不变性。然后,我们提出了一个采样层,用于提取时间持久的信号。它将鼓励节点在时间跨度视图下保持一致的局部和全局表示,即在时间上具有平移不变性。大量的实验证明了该方法在七个数据集上的有效性和高效性,它在性能上优于八个无监督最先进的基线方法,并在竞争性方面击败了四种半监督方法。与现有的动态图方法相比,在七个数据集上,模型参数数量和训练时间分别平均减少了2,001.86倍和130.31倍。
研究成果三:基于对比学习的两阶段命名实体识别方法
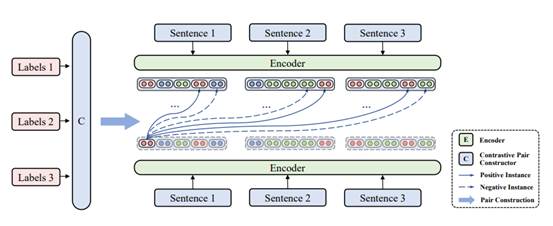
序列标注是中文命名实体识别(NER)中最常用的方法。然而,传统的序列标注方法根据实体内部的位置将标记划分为不同的类别。因此,同一个实体中的不同标记可能被学习为在目标表示空间中是孤立且不相关的表示,最终可能对后续的标记分类性能产生负面影响。在本文中,我们指出并定义了这个问题,称之为“标签语义中的实体表示分割”。然后,我们提出了NerCo:具有对比学习的命名实体识别,这是一种新颖的NER框架,可以更好地利用标记数据并避免上述问题。根据预训练和微调的范式,NerCo首先引导编码器学习基于标签语义的强大表示,通过汇集同一语义类别的编码标记表示,并将不同类别的标记表示分开。随后,NerCo微调学习的编码器进行最终的实体预测。对几个数据集进行的大量实验证明,我们的框架可以持续改进基线,并达到最先进的性能水平。
研究成果四:基于渐进式推理的分布外泛化图表示学习
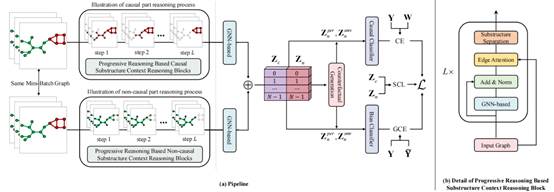
提出了一种通过渐进推理来学习图的因果不变性的新架构。它将识别因果子结构和特征的复杂问题分解为从简单到困难的多个中间推理步骤,以模拟人类在解决复杂问题时所使用的认知过程,旨在增强泛化能力。具体来说,每个推理步骤都能从上一个推理步骤中学习到的因果子结构中进一步分离出具有高度置信度的非因果子结构。每个推理步骤的建模都涉及到一个设计良好的子结构上下文推理块。通过堆叠多个这样的块,模仿一步一步的思维过程来完善准确的答案。在3个动态图数据集中,与17个基线模型相比,我们提出的方法平均相较于当前最为先进的方法提升了4.91%。在分布变化更严重的数据集的情况下,性能提高可高达6.86%。

