


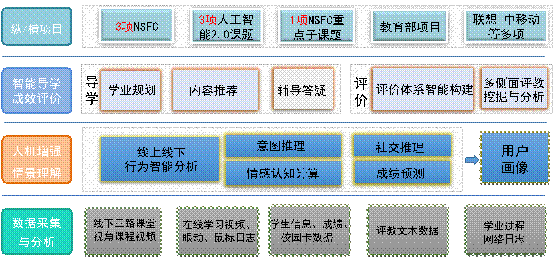
小组致力于智慧教育与大数据分析关键技术、系统研制与应用研究。基于人工智能、教育学理论与方法,研究在线和线下教育,跨模态数据用户行为、表情识别、认知状态预测与意图推理方法;采用机器学习和数据挖掘等方法,实现用户精准画像;用复杂网络方法分析用户社会关系,并进行海量资源下的个性化推荐研究;探索领域知识深度关联挖掘、融合方法,支撑智慧教育等领域大数据驱动的计算服务及应用。
小组目前主力承担/参与科技部科技创新2030-人工智能重大项目(3项)、国家自然科学基金群体/重点/面上项目(5项);已完成国家自然科学基金面上项目4项,国家“十二五”科技支撑计划/国家863计划等课题/子课题3项;研究成果已在多个国家级平台、省部级、校级单位部署与应用,在IEEE TKDE、IEEE TASE、AAAI、ICDE、EMNLP等国内外著名期刊与会议发表论文100余篇以上,获得多项发明专利和软件著作权授权,获国家科技进步奖二等奖1项、国家教学成果奖二等奖2项及省部科技进步奖3项、教学成果特等奖2项。
小组培养出许多优秀人才,多名实训本科生推荐到CMU、TAMU等大学、美国硅谷多家公司工作或学习;多名优秀毕业生任职高级教授、就职于阿里、百度、华为诺亚方舟、腾讯、中国银行、美团等优秀企业或者在北美名校大学攻读完成博士学位。
智慧教育与教育大数据小组致力于大数据挖掘与智慧教育应用研究。基于人工智能、教育学理论与方法,创新性地提出师机生复合认知主体概念、协同演化的认知机理及智慧教育新范式,研究跨模态数据用户行为、情感、意图推理、认知识别方法,实现用户精准画像,并进行海量资源下的个性化推荐研究;探索新时代下数据与知识双驱动的智能计算,及其在教学评价中的应用,促进教育创新发展。
同时,也探索将最新研究成果在航空、电信、电子商务等领域创新应用。
田锋,博士,西安交通大学计算机学院教授,博士生导师,IEEE高级会员,CCF会员,王宽诚育才奖获得者,大数据算法与分析技术国家工程实验室大数据算法测试与示范应用中心主任,中国自动化学会智慧教育专委会委员,中国教育发展战略学会教育大数据专委会常务理事,教育部智能网络与网络安全重点实验室成员,陕西省大数据知识工程重点实验室成员。主持或参与国家自然科学基金、国家科技支撑计划等十多项国家科研项目和微软百度的多项横向课题。成果已经在高等教育和国家税务等行业得到应用,多项成果被教育部、中国电子协会、陕西省教育厅组织单位的鉴定委员会评价为国际领先;获国家科技进步二等奖1项,国家教学成果二等奖2项,省部级科技进步奖3项,CCF科技进步一等奖1项等。近年来在IEEE TKDE、IEEE TASE、AAAI、IEEE ICDE等国内外期刊会议上发表100余篇论文;申请国家发明专利10+项,已授权7项;参与出版著作2部。研究方向:人工智能与智慧教育、大数据挖掘应用。
陈妍 博士,副教授,博导。中国计算机学会网络与数据通信专业委员会委员。主持国家自然科学基金1项,主持重点研发子课题1项,主持国家自然科学基金重大项目子课题1项,省部级项目2项,横向课题6项。作为主要成员参加重点研发项目、国家杰出青年基金、国家自然科学基金等多项课题。以第一作者在国际内外期刊、高水平国际会议上发表论文20余篇,申请及授权专利10余项。主编教材2部,参编教材6部。获得西安交通大学优秀教材一等奖1项,二等奖2项。获中国自动化学会科技进步特等奖等荣誉。主讲本科生课程:《计算机网络原理》。研究方向:智能网络学习环境理论与技术。
朱海萍,博士,西安交通大学计算机学院副教授。2013.8~2014.8美国爱荷华州立大学计算机科学系访问学者,主要科研方向是教育大数据挖掘与分析,个性化推荐。骨干参与了国家重点研发计划项目、国家自然科学基金、863计划等多项研究课题,主持国家自然科学基金、陕西省自然科学基金项目、国家自然科学基金面上项目等8项,获陕西省科学技术奖一等奖(第8完成人)、陕西省高等学校科学技术一等奖(第6完成人)和西安市科技进步奖(第3完成人)。发表学术论文20余篇,申请及授权专利多项,参编《计算机网络原理》等教材3部。2013年参与主讲的课程“计算机网络原理”获国家精品资源共享建设项目,系国家教学团队“计算机网络与系统结构”、教育部“智能e-Learning系统理论与技术创新团队”成员。
老师:田锋、陈妍、朱海萍
博 士:齐天亮、籍伟华、南方、安文斌、孙士林、刘启东
研 三:王耀智、蒋诗瑶、白宇翔、李玉杰、刘嘉欣、廖思霁、车书玮、赵怡菲
研 二:姚煜哲、林浩南、张恒、朱辉、李文浩、施文楷、周思璇、郝怡然、刘庆、沈铭宇、王子瑜
研 一:沈欣玥、王辰阳、苗浩楠、江智豪、李岩、孙玉琪、宣珍珍、李可玄、李嘉源、陈增一、LorenzoBiasiolo(意大利米兰理工大学)
成果一:基于鲁棒伪标签训练和源域联合训练的新用户意图发现
为了能从新数据中进行新标签的发现,课题组提出了一种基于鲁棒伪标签训练和源域再训练的模型。该模型通过特征提取器Extractor对输入文本进行特征提取,并利用聚类模块Generator为未标注数据生成伪标签,同时,课题组提出了一种矫正器模块Corrector来对Generator生成的伪标签进行矫正,使得所提模型产生的伪标签比普通方法产生的伪标签更加鲁棒。之后,利用生成的伪标签来对模型进行训练。同时,为了解决知识遗忘的问题,提出了一种源域再训练策略。最后,通过对Generator,Extractor,Corrector的输出进行投票组合,得到较为鲁棒的预测结果。模型框架如图1所示, 论文发表最具期刊IEEE Intelligent Systems.
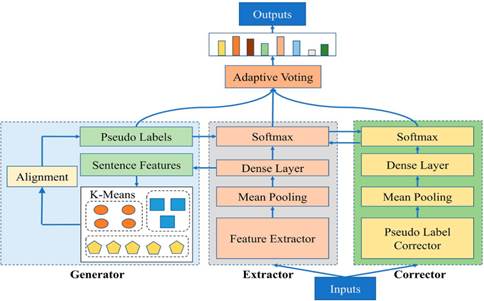
图1 论文模型框架图
为了验证模型的有效性,课题组在三个共有数据集上进行了实验,并与最新的方法进行了比较,我们的模型在全部数据集和评价指标上超越了已有方法。相较于此前的算法提升如下表所示:
准确率提升 |
调整兰德系数提升 |
互信息熵提升 |
|
DAC(AAAI 2021) |
6.0% |
4.8% |
1.8% |
CDAC+(AAAI 2020) |
15.0% |
21.1% |
10.1% |
ODC(CVPR 2020) |
9.3% |
7.2% |
2.6% |
该论文被多个国际顶级会议、期刊(如AAAI 2024,EMNLP 2023等)论文引用,目前被引用次数为4次。该论文项目代码已开源,地址为https://github.com/Lackel/PTJN。
成果二:基于降噪邻域聚合的细粒度类别发现
从粗粒度标注数据中发现细粒度类别是一项具有挑战性的任务,以往的研究主要关注实例级的判别来学习低级的特征,但却忽略了数据之间的语义相似性,这可能会阻碍这些模型学习到紧凑的聚类表示。在本文中,我们提出了降噪邻域聚合模型。具体地,我们检索查询 k 个近邻作为数据的正样本来捕捉数据之间的语义相似性,然后聚合这些近邻的信息来学习紧凑的聚类表示,同时我们提出了三条原则来过滤假近邻样本,以获得更好的表征学习效果。 论文发表于CCF-B类会议EMNLP 2023。
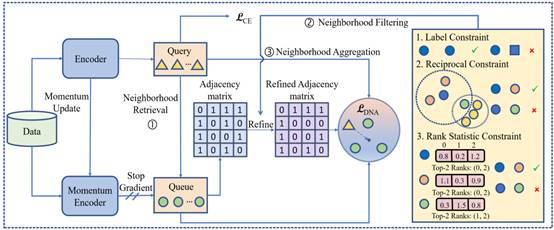
图2 论文模型框架图
为了验证模型的有效性,课题组在三个共有数据集上进行了实验,并与最新的方法进行了比较,我们的模型在全部数据集和评价指标上超越了已有方法。相较于此前的算法提升如下表所示:
准确率提升 |
调整兰德系数提升 |
互信息熵提升 |
|
WSCL(EMNLP 2022) |
11.4% |
13.6% |
4.9% |
SimCSE(EMNLP 2021) |
35.1% |
33.8% |
13.7% |
Ancor(CVPR 2021) |
38.1% |
39.0% |
17.1% |
该论文被多个国际顶级会议、期刊(如AAAI 2024等)论文引用,目前被引用次数为2次。该论文项目代码已开源,地址为https://github.com/Lackel/DNA。
成果三:基于解耦原型网络的广义类别发现
现有的广义类别发现方法没有考虑已知类别和新类别之间的差异,而是以耦合的方式共同学习它们的表征,这可能会损害其模型的泛化能力和判别能力。此外,这种耦合的训练方式还阻止了这些模型将已知类别的类别特定知识从已标注数据显式地迁移到未标注数据,这可能会导致类别相关的高级语义信息丢失,从而影响模型性能。为了解决上述局限性,我们提出了一种名为解耦原型网络(DPN)的新型模型。我们首先提出了广义类别发现任务对已知类别和新类别的不同训练目标。为了解耦已知类别和新类别,我们提出将其转化为类别原型的双向匹配问题,DPN 不仅能将已知类别和新类别解耦,从而有效地实现对已知类和新类的不同的训练目标,还能将标注数据和未标注数据中的已知类别对齐,从而显式地迁移类别特定的知识,并捕捉类别相关的高级语义信息。此外,DPN 还能通过我们提出的语义感知原型学习为已知类别和新类别学习更好的判别特征,同时减轻伪标签带来的噪声影响。DPN的整体框架如下图所示。论文发表于CCF-A类会议AAAI 2023。
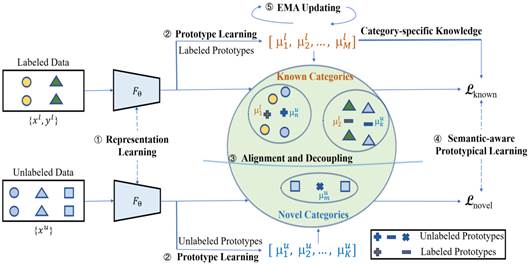
图3 论文模型框架图
论文中提出的算法DPN在三个基准数据集的整体准确率、已知类准确率、新类准确率三个指标上都取得了最优的性能,相较于此前的算法提升如下表所示:
整体准确率提升 |
已知类准确率提升 |
新类准确率提升 |
|
GCD(CVPR 2022) |
8.2% |
4.1% |
20.3% |
Self(AAAI 2022) |
15.4% |
13.0% |
15.1% |
DAC(AAAI 2021) |
9.1% |
8.1% |
12.2% |
该论文被多个国际顶级会议、期刊(如NIPS 2023,EMNLP 2023,IEEE Intelligent System等)论文引用,目前被引用次数为11次。该论文项目代码已开源,地址为https://github.com/Lackel/DPN,获得12次下载,26个star。
成果四:基于扩散加权图框架的广义类别发现
现有的广义类别发现方法大都基于固定的语义相似度阈值生成伪标签以微调语言模型。若增大语义相似度的筛选阈值,松弛超球面,则易引入大量异类噪声;反之,若减小语义相似度的筛选阈值,收缩超球面,则损失了大量超球面之外的同类监督信号。该范式难以获取既可靠又足量的伪标签,阻碍了新意图簇的形成。为此,我们提出了一个扩散加权图框架,能够同时捕获数据间的语义相似度和固有的结构关系来平衡伪标签的数量与质量。该框架由两部分构成:基于扩散加权图的模型微调和基于图平滑滤波器的模型推理。对于模型微调,首先通过建模近邻关系和定义扩散操作构造扩散加权图,然后依据结构图的连通性与连通密度采样并附权对比近邻样本,最后同时进行局部视角的近邻对比学习和全局视角的自训练;对于模型推理,首先采用相同方式构图,然后依据结构图构造平滑滤波器,最后平滑表征、滤除噪声并完成聚类。得益于扩散加权图,该模型能够自适应地采样和过滤对比样本,极大地提升了表征质量。DWGF的整体框架如下图所示。论文发表于CCF-B类会议EMNLP 2023。
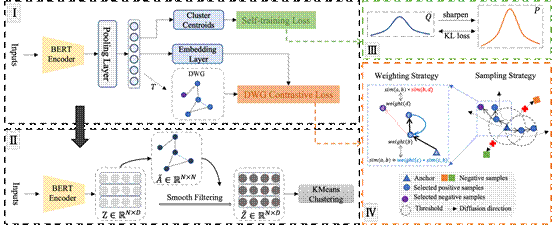
图4 论文模型框架图
论文中提出的算法DWGF在三个基准数据集上的聚类准确率、兰德系数、标准化互信息三个指标上都取得了最优的性能,相较于此前的算法提升如下表所示:
聚类准确率提升 |
兰德系数提升 |
标准化互信息提升 |
|
DAC(AAAI 2021) |
10.45% |
13.34% |
5.47% |
DPN(AAAI 2023) |
5.07% |
5.67% |
0.98% |
CLNN(ACL 2022) |
2.27% |
1.4% |
0.52% |
该论文项目代码已开源,地址为https://github.com/yibai-shi/DWGF.

